- Lawyers
- Managers
- Policy makers
- Developers of Internet Applications
- Anyone who uses the Web
The last is the most important. Understanding how the Internet works is essential to anyone who wants to have an informed opinion on Internet policy. Like most Internet activists, I believe that we must fight to keep the Internet open and free but I resist the attempts to reduce those goals to simplistic slogans like 'Net Neutrality' that can mean anything an Industry lobbyist wants them to mean.
In these pages I present my personal description of the Web architecture. It is intended to be descriptive rather than proscriptive, describing the Internet as it is rather than how the architects might have intended it to be. As such, there are significant differences between my description of the Internet architecture and the one that traditionally appears in Computer Science text books. In particular, my model:
- Explicitly includes the role of Internet infrastructures, BGP, DNS and WebPKI.
- Is applicable to both the Inter-Network and local networks.
- Incorporates firewalls, Virtual Private Networks (VPN), Software Defined Networking (SDN).
- Describes the interactions between the parts of the Internet rather than the specific manner in which they are implemented.
For a longer explanation of why I have taken this approach, click here. Otherwise, read on.
What is Packet Data Communication?
Alexander Graham Bell's first working prototype of a telephone consisted of a microphone in one room connected to a speaker in another by a piece of wire. Shortly after giving the famous first telephone message "Mr Watson come here, I need you", a second wire was added to allow two way communication. From that point on (1876) to the effective dissolution of the telephone network into the Internet in the early 21st century, the telephone network has performed one function in essentially the same fashion. The function of the telephone network is transmitting voice communications and that function is achieved by establishing a physical or logical circuit connecting pairs of transmitters and receivers.

Packet data communications work in a very different fashion. Instead of trying to send a complete message in one go, long messages are split up into chunks. Each chunk is a packet. Sending data as a series of chunks is a lot more efficient than setting up a virtual circuit because we only send as many or as few packets as we need.
In a normal conversation, only one person is speaking at once. But the circuit switched telephone network always allocates two communication channels, even though at least one circuit is usually silent at a given moment in time.
Another important advantage of packet data communication is that we can always make use of the maximum communication capacity available. In a circuit switched network we have to decide in advance how much capacity we need and changing that allotment incurs significant penalty.
Protocol Stacks
Sending data through a packet switched network is a bit like trying to send a novel using a stack of postcards: The receiver is only going to consider the process a success if what arrives can be put back in order so that what comes out is a book.
What we need are a set of rules that let us break a message up into chuncks at one end of the communication and reassemble it at the other. For some not very good historical reasons the rules for doing this are called 'Transport' and the rules that determine how packets move across the network are called 'Network'. The transport code sits on top of the network code like layers in a cake. This is called a 'stack':

Until the arrival of the Web in the mid 1990s, there were dozens of network protocols in common use, each of which had different rules for how the transport and network layers interacted. The rules for a given packet data network design might vary by a little or a lot but all the successful designs made use of a 'stack' model and all observed the same rules for applying that model:
- Each layer in the stack represents a different level of abstraction with the topmost layer being the most abstract and the lowest describing the actual physical network.
- Each layer in the stack only interacts with the layer immediately above and below it.
One of the consequences of the second rule is that when you are connecting to Facebook using a Web browser, you can use the same Web browser and it works in exactly the same way whether you are connected by a WiFi wireless network connection or a wired Ethernet connection. If the Web browser had needed special code to work with WiFi wireless it is rather unlikely that it would have been a success.
Reinventing the Stack
The network stack model has been applied since the 1970s. Like most such models, the main benefit of the stack model is that it is the one most people in the business are familiar with. This does not make it a good model.
The most commonly applied version of the stack model is the seven layer OSI stack which creates even mode
The traditional model emerged at a time when computer systems were designed by describing how their function would be achieved. In the modern approach we separate the description of a function (the specification) from the implementation (program code). Applied to the network stack, we are interested in the interactions (interfaces) between the layers rather than the implementation of the layers themselves.
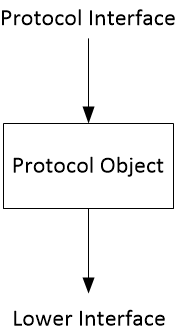
At each layer in the stack, messages consist of a 'head' and a 'body'. The head is the control information that describes how the information passes through the network that applies at that level. The body contains the data being sent by the layer above.
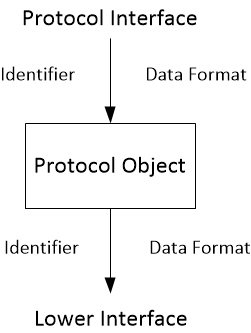
Each layer in the stack can define as much or as little control information as it needs. But the only control information that crosses the interfaces between layers are the identifiers that specify the source and destination of the messages. Different identifiers are used at different layers in the stack. A network analyzer looking at the traffic in use due to your downloading this page might see the following identifiers in use:
- http://www.hallambaker.com/Professional/Architecture
- Uniform Resource Identifier (URI) identifying the location of the page.
- www.hallambaker.com
- DNS Name of the Web Server where the site is hosted
- 10.1.2.3:80
- Internet Protocol (IP) address and port number of the host service
- 8943 3549 701
- Autonomous Service Number (ASN) for my ISP (AS701 UUNET)
- /dev/eth42
- Router link assignment
Adding descriptions of the identifiers and data representations that define an interface we get:
We have a description of the interfaces between the layers but we don't explain how DNS names get turned into IP addresses or IP addresses to ASN numbers. The mapping of one identifier form to another is the function of the Internet infrastructures, the DNS, the BGP and the Web PKI.
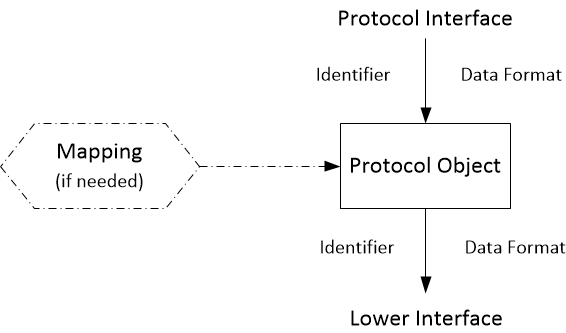
This network model isn't very different from or more complicated than the traditional one but it allows us to give a much better description of the Internet. It also allows us to describe the role of the large and growing number of technologies that don't have any place in the traditional model:
What is the Internet
According to common use, the Internet can mean one or all of three very different things:
- The computer programs (applications) that make use of the Internet to communicate.
- Any computer network that is connected to the Internet.
- The Inter-network that connects computer networks to form the Internet.
Rather than arguing over semantics and insisting that only the last of these definitions is 'correct', the Internet model we need is one that covers all three. The Internet exists only to service the applications that make use of it. It is the Internet applications that give the Internet meaning. And in the modern Internet those applications communicate to the Inter-network through the medium of at least one and more frequently more than one other network.
[TBS:Diagram showing Applications, Network and Inter-Network]
The starting point for a discussion of the Internet then, is to describe the Inter-Network and how it is different from a network.
The Inter-Work is a Network of Networks.
According to some Internet historians, the Internet began at 22:30 hours on October 29, 1969 when the first ARPANET link was established between the University of California, Los Angeles (UCLA) and the Stanford Research Institute (SRI). According to others it began much earlier in April 1963 when J.C.R. Licklider proposed the idea of an 'Intergalactic Computer Network'. But while these are certainly important dates in Internet history, they mark the start of the process that created the Internet, not its completion.
If a single date was to be given for the creation of the Internet it would be January 1, 1983, the day known as 'flag day' when the Network Control Program (NCP) that had been developed to support the ARPANET was replaced with the Transmission Control Protocol (TCP). As we will see, TCP is one of the core pieces of the Internet architecture but the reason that the NCP/TCP transition was so important is social not technical.
On flag day, the Internet had over a thousand hosts at several hundred different institutions. The organizers had been prepared for difficulties but the experience was far worse than anyone had predicted. Internet growth, already exponential would make future protocol transitions even worse. Flag day was the last and single most important experiment of the ARPANET because it was the experiment that proved that the operation of a network of networks was completely different from the operation of a network.
At the time, computers were large, expensive and required a dedicated IT staff to keep them running. A flag day was the generally preferred way to apply operating system updates to every machine on a university campus. On the appointed day and time, the machines would shut down for an hour or so and when they came back up they would all be running the new operating system. What was the common sense approach to managing a campus network was a disaster at Internet scale. To avoid interruption of service, every machine would have to make the switch at the same time and the software for the new TCP protocol would have to work perfectly first time.
As you can probably guess, neither condition was met. Some Internet nodes made the transition successfully but many did not. Different sites had wildly different hardware, software and resources. What was a trivial change at one site might require several weeks of programmer time to write a new driver at another. Even worse, unless a site had access to another wide area network, there was no email and FTP until the problems were fixed. Any code updates would have to arrive on a nine track tape.
Internet Architecture
Flag day provided proof that the design of an Inter-network, a network of networks must meet a constraint that does not apply to the design of a network: A network architecture may assume a central point of administration and control, an Inter-network cannot. This realization (or more accurately, confirmation of what some had already proposed) led to the definition of 'the Internet' as the inter-network that connects local networks together. The characteristics of the Internet would be:
- The Internet is a network of networks, each network being under independent administration and control.
- There will be no flag days. All protocol transitions must support a gradual transition between the old and the new technologies.
- Internet Protocol is the only protocol used for communication between networks
- Functions requiring maintenance of state will be performed at the end points of the communication.
The principle that there is only one packet layer protocol, the Internet Protocol (IP) is known as the 'thin waist'. The Internet isn't limited to one physical medium or purpose. The Internet can be used on wired, optical or wireless technologies. The only difference between 14Kb/s dial up modem that was the norm in the 1980s and the Gigabit broadband Google is rolling out in parts of the US is the speed. The Internet is used for mail, the Web, chat, video, online banking, logistics and tens of thousands of other purposes.
What the Internet architecture did not and does not require is 'IP-everywhere'. Many network protocols were in use at time the Internet architecture was being developed. IP was sold as the glue that would make these networks work together, not a replacement for protocols such as DECNET Phase IV or IBM's SNA. But this turned out to be a distinction without a difference. While there were many technical differences between the proprietary network technologies being sold by IBM, DEC, Apple, Novel and the rest, there were remarkably few technical advantages of one over another.
TCP/IP was the only protocol that was designed to connect proprietary networks and it became the protocol that every vendor had to be support. Once network managers realized they could meet all their local and inter-site needs with a single network technology, they quickly lost interest in supporting anything else.
There is still a few remaining areas where IP has not yet taken over, mostly involving short distance and device to device communictions. A $35 computer such as a Raspberry Pi can handle a TCP/IP stack with ease. This is not the case for some the 8 and 16 bit processors used to provide 'smart' functionality to a lightswitch or the like. Though the reason vendors don't provide TCP/IP based connectivity is probably not the additional cost of a processor that is suited.
The Early Internet Stack
The Internet architecture has always followed a layer model. In the early Internet architecture, packet data transmission was the responsibility of the Internet Protocol 'IP' and the job of reassembling packets to create data 'streams' is the job of the Transmission Control Protocol 'TCP'. Used together, these are known as TCP/IP:

While every packet data network has a network layer and a transport layer, the way these layers interacted was very different to earlier designs. There is no guarantee that packets sent from one Internet node to another will:
- Follow the same path,
- Arrive in the order they were sent
- Arrive at all
Counter-intuitively, the last point is the chief technical difference that has made the Internet so successful. The telephone network approach to reliability was to make sure that every part of the system was as close to 100% reliability as possible. The Internet approach is to accept that failures are inevitable and work around them.
Avoiding packet loss requires the switching nodes of a network be aware of the state of the entire network; which nodes are down, which links are congested, etc. Maintaining this awareness is very difficult and requires a considerable amount of communication overhead. As the network expands, so does the communication overhead. The near perfect reliability of the telephone network core was achieved by dividing it into what were in effect two separate networks; the data plane and control plane.
The Internet architects looked at the problem of making the network reliable in a different way. All that mattered was that the network appear to be reliable to the application. Whether a particular packet arrived at its intended destination didn't matter if it could be resent. Instead of trying to achieve perfect reliability in the network layer, the Internet architects decided to accept the unreliability of the network as a constraint and provide reliability at the transport layer.
This approach allowed the Internet architects to simplify the design of the Internet core and to push out the complicated work of providing reliability to the edges. When an Internet s witching node (aka 'router') gets overloaded with more packets coming in than it can cope with, the excess is simply discarded. The Internet does make a distinction between control traffic and data traffic but they are not separated. The argument for this approach to networking is known as the end-to-end principle.
To see how the end to end principle simplifies the Internet architecture, consider a communication between Hosts A and B passing through switches X and Y:
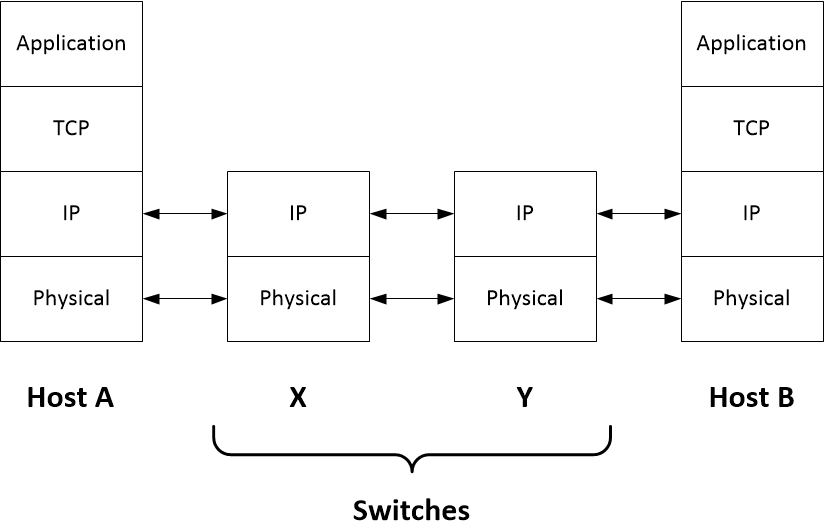
Every device has a physical connection and runs the IP protocol. But only the hosts at the end points implement the TCP part of the protocol. This has important consequences:
- Simplifying the switching nodes makes it easier to make them faster.
- We can change the behavior of the Internet by modifying or replacing TCP at the hosts without having to change every on switch in the path.
TCP has not changed very often, but it has changed. Specifications with important changes were published in 1989, 1997, 1999 and 2009. Needs have changed as the Internet has expanded from a few thousand users in 1983 to three billion in 2015.
Faster devices do not necessarily mean better performance. At the time of writing we are currently experiencing a problem called buffer bloat which is a principle cause of the sudden slowdowns that can make Internet videos or voice communications rather unpleasant at times.
The Modern Internet Protocol Stack
TCP and IP are still part of the Internet architecture today but there is quite a bit more to the Internet architecture besides.
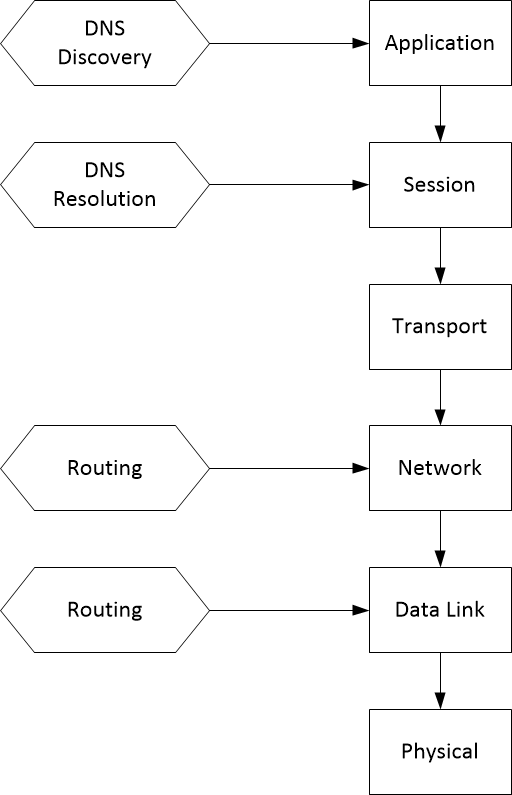
In addition to having more layers, the modern Internet is better described by explaining what the layers do rather than how this is done. To do this we need to look at the interactions between the layers rather than the layers themselves.
Another important aspect of the modern Internet is that it is now supported by three infrastructures that did not and could not have existed at the start:
- WebPKI.
- Domain Name System (DNS)
- Border Gateway Protocol (BGP)
These infrastructures are not just critical to the functioning of the modern Internet, they are also potential control points. As a result they are the highest leverage points of attack. Anyone who controls any one of these infrastructures has a great deal of control of the Internet. To control all three would provide almost complete control of the global communication infrastructure.
For this reason, the three principle Internet infrastructures are sometimes referred to as 'rings of power' after J.R.R. Tolkein's Lord of the Rings. A large fraction of what is known as 'Internet governance' involves fights over apparent or actual control over these rings of power.
The question of who controls the Internet has become a major concern in international politics. There are even a formal treaty between Russia and China pledging the countries to work together to prevent 'domination' of information infrastructures and what they call 'information terrorism'. The latter apparently meaning 'criticizing either of our governments'.
This is a design issue as well as a policy issue. The best way to avoid having the Internet being the center of this sort of dispute is to design it in a way that eliminates as many potential control points as possible and reduces the degree of control any one party can exercise.
One of the most important mitigation controls is the ability to establish independent control infrastructures. The DNS is purposely designed with a distinction between different levels of administration.